Intel oneAPI Math Kernel Library
 Biblioteka numeryczna zawierająca funkcje algebry liniowej, przetwarzania liczb zmiennoprzecinkowych, szybkiej transformacji Fouriera (FFT) i funkcji matematyki wektorowej. Intel Math Kernel Library umożliwia zwiększenie wydajności dla oprogramowania finansowego, naukowego i inżynierskiego. Jest to zoptymalizowana biblioteka dla procesorów Intel, przystosowana do wielowątkowego przetwarzania równoległego w systemach wieloprocesorowych. Biblioteka jest też oferowana w opcji Cluster Edition, która dodatkowo zawiera skalowalną wersję biblioteki LAPACK (ScaLAPAC) oraz procedury FFT przystosowane do przetwarzania w systemach z rozproszoną pamięcią.
Biblioteka numeryczna zawierająca funkcje algebry liniowej, przetwarzania liczb zmiennoprzecinkowych, szybkiej transformacji Fouriera (FFT) i funkcji matematyki wektorowej. Intel Math Kernel Library umożliwia zwiększenie wydajności dla oprogramowania finansowego, naukowego i inżynierskiego. Jest to zoptymalizowana biblioteka dla procesorów Intel, przystosowana do wielowątkowego przetwarzania równoległego w systemach wieloprocesorowych. Biblioteka jest też oferowana w opcji Cluster Edition, która dodatkowo zawiera skalowalną wersję biblioteki LAPACK (ScaLAPAC) oraz procedury FFT przystosowane do przetwarzania w systemach z rozproszoną pamięcią.
Podstawowe cechy biblioteki:
Zbiory procedur zaimplementowane w oneAPI MKL:
Biblioteka numeryczna zawierająca funkcje algebry liniowej, przetwarzania liczb zmiennoprzecinkowych, szybkiej transformacji Fouriera (FFT) i funkcji matematyki wektorowej. Intel Math Kernel Library umożliwia zwiększenie wydajności dla oprogramowania finansowego, naukowego i inżynierskiego. Jest to zoptymalizowana biblioteka dla procesorów Intel, przystosowana do wielowątkowego przetwarzania równoległego w systemach wieloprocesorowych. Biblioteka jest też oferowana w opcji Cluster Edition, która dodatkowo zawiera skalowalną wersję biblioteki LAPACK (ScaLAPAC) oraz procedury FFT przystosowane do przetwarzania w systemach z rozproszoną pamięcią.Podstawowe cechy biblioteki:
- Skalowalność: cecha ta pozwala na użycie biblioteki w systemach o różnej liczbie procesorów równoległych, bez konieczności zmiany kodu źródłowego
- Wielowątkowość: biblioteka może być bezpiecznie używana w systemach wielowątkowych z wielordzeniowymi procesorami lub w systemach wieloprocesorowych
- Wysoka wydajność: biblioteka zawiera optymalizowane ze względu na czas wykonywania procedury obliczeń matematycznych z grup LAPACK, BLAS, DFTs, FFTs, VML i VSL, co jest gwarancją ich wysokiej wydajności.
- Automatyczna detekcja procesora: prowadzona na etapie wykonywania programu detekcja typu procesora pozwala zastosować do obliczeń kod optymalny dla danej architektury.
- Optymalizacja: biblioteka zawiera alternatywne kody procedur matematycznych dla procesorów Intel Xeon, Intel Core oraz Intel Atom, jest to cecha, która w przypadku innych bibliotek wymaga stosowania różnych ich wersji dla tych procesorów.
- Licencja run-time: licencja biblioteki oneAPI MKL pozwala na bezpłatną ich redystrybucję w formie aplikacji, której są częścią składową.
- Dostępność dla wielu platform: to samo API dla aplikacji tworzonych na systemach Windows, Linux oraz macOS. Natywnie wsparcie dla języków C, C++ oraz Fortran, jak również Java, C#/.NET oraz Python w opcji Cross-language.
Zbiory procedur zaimplementowane w oneAPI MKL:
- LAPACK (Linear Algebra PACKage) - zbiór procedur numerycznych z zakresu algebry liniowej, napisanych w Fortranie. Zawiera procedury służące do rozwiązywania układów równań liniowych, aproksymacji liniowej, rozwiązywania zagadnień własnych i wyznaczania rozkładu macierzy według wartości szczególnych
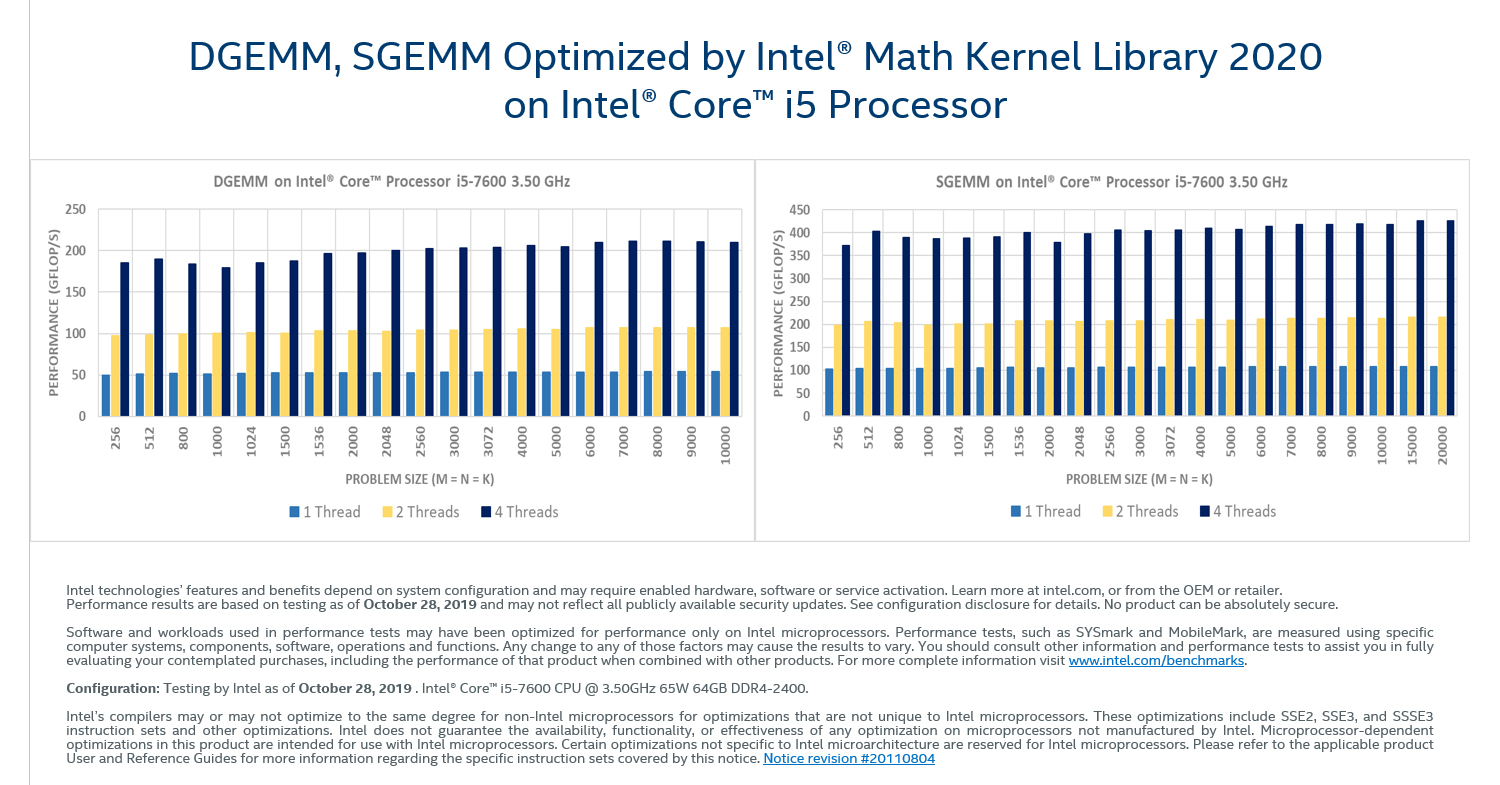 Kliknij aby powiększyć
Kliknij aby powiększyć
- VML (Vector Math Library) - zbiór wysoko zoptymalizowanych implementacji funkcji matematycznych (trygonometryczne, wykładnicze, logarytmiczne, hiperboliczne, potęgowe itp), operujących na rzeczywistych argumentach wektora
- VS (Vector Statistics) - operacje statystyczne , wliczając w to generowanie liczb losowych, miary rozkładów oraz operacje splotu rozkładów.
 Kliknij aby powiększyć
Kliknij aby powiększyć
- BLAS (Basic Linear Algebra Subprograms) - wysokiej jakości procedury wykonujące podstawowe operacje algebraiczne. Poziom pierwszy obejmuje operacje typu wektor - wektor, poziom drugi to operacje macierz - wektor, zaś poziom trzeci dotyczy operacji typu macierz - macierz. Procedury BLAS są wykorzystywane przez wiele innych pakietów, np. LAPACK i LINPACK
- FFT (Fast Fourier Transform) - szybka transformata Fouriera jest używana w systemach liniowych, konstruowaniu anten, pomiarach optycznych, modelowaniu zdarzeń losowych, teorii prawdopodobieństwa, fizyce kwantowej, przy określaniu różnych wartości brzegowych, a także astrofizyce i innych. Udoskonalona szybka transformata Fouriera charakteryzuje się wysoką wydajnością i przystosowane są do wielowątkowego przetwarzania na maszynach wieloprocesorowych.
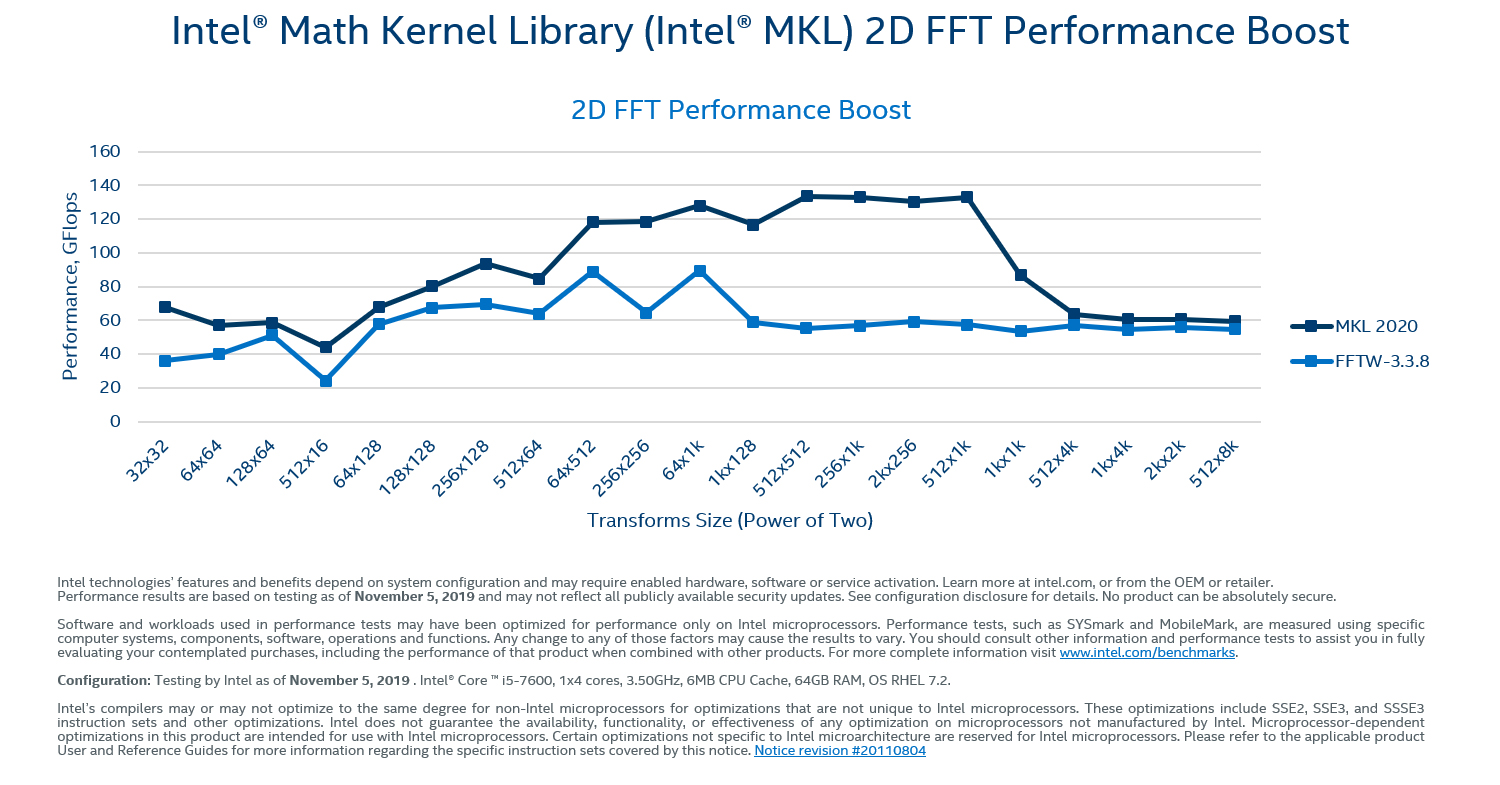 Kliknij aby powiększyć
Kliknij aby powiększyć
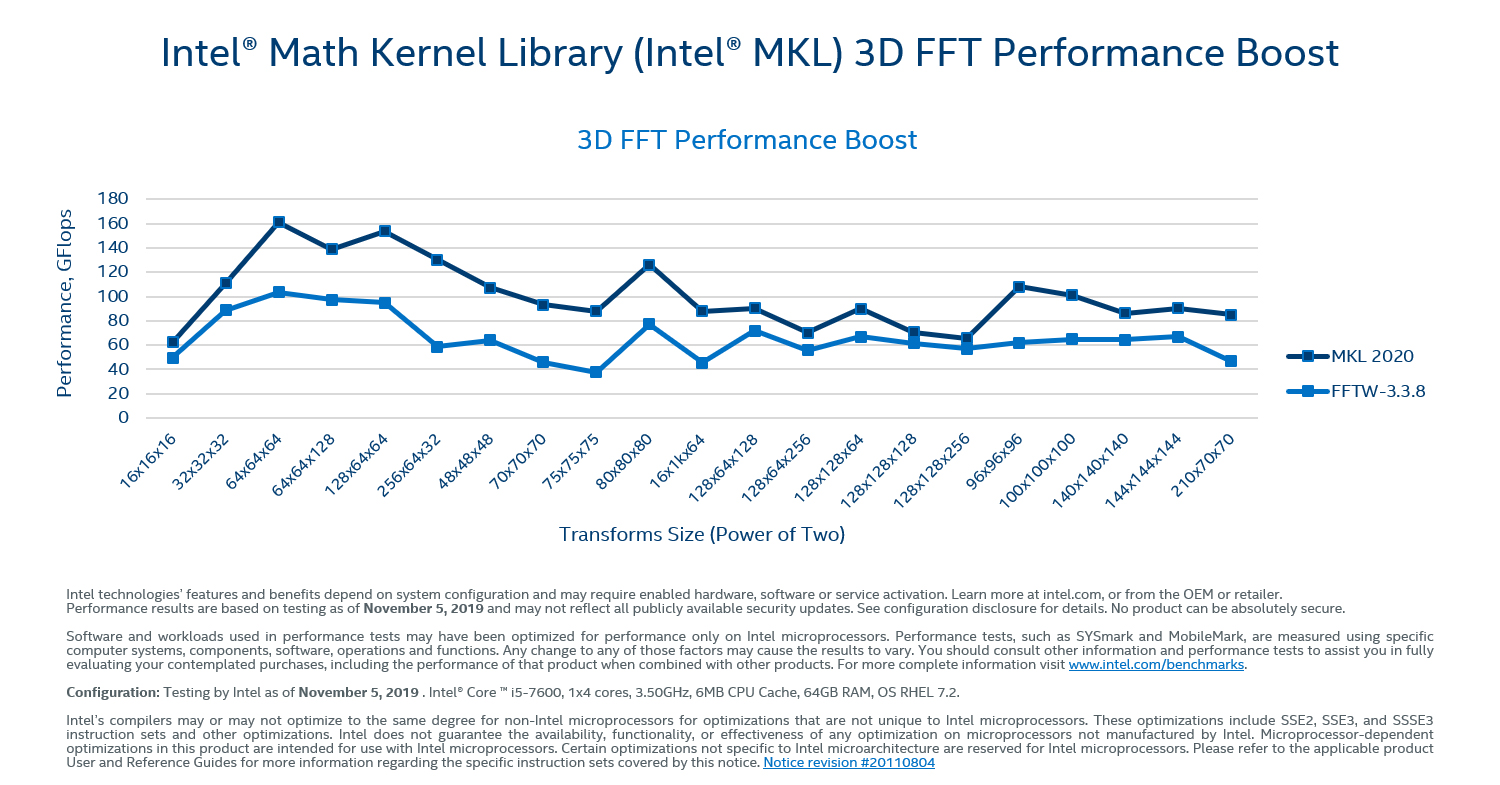 Kliknij aby powiększyć
Kliknij aby powiększyć
- DNN (Deep Neural Networks) - zbiór funkcji usprawniających uczenie maszynowe zoptymalizowanych do pracy w procesorach Intel. Zawiera procedury niezbędne do przyspieszania topologii sieci neuronowych do rozpoznawania obrazów, włącznie z AlexNet, VGG, GoogleNet oraz ResNet, jak również operacje splotu, funkcje aktywacji neuronu i funkcje normalizacji.
- PARDISO Direct Sparse Solver: procedury algebry liniowej macierzy rzadkich przystosowane do wielowątkowej pracy równoległej w systemach wieloprocesorowych
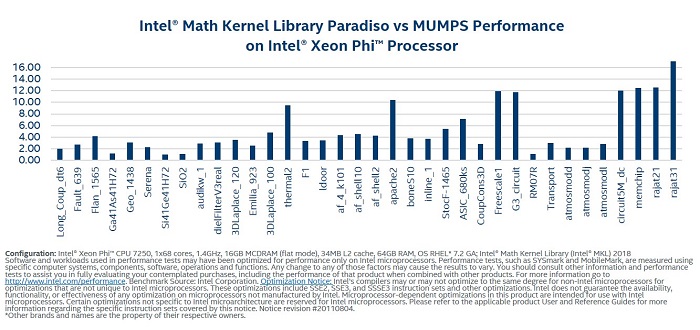 Kliknij aby powiększyć
Kliknij aby powiększyć

Kliknij aby powiększyć