NOWOŚCI W WERSJI 13
Nowe funkcje i możliwości najnowszej wersji programu SigmaPlot 13 to m.in:
- Funkcje wykresów
- Wykres typu Forest Plot
- Wykres Kernel Density
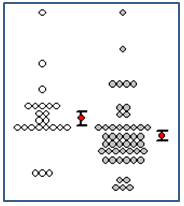
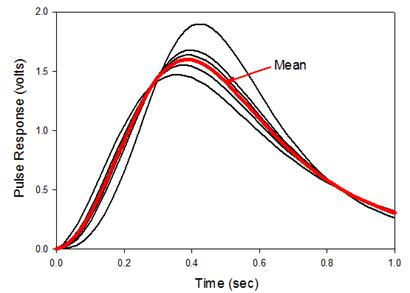
Wykres Kernel Density pozwala oszacować podstawowy rozkład danych. Można go porównać do schodkowego histogramu. Ma swoje zalety(brak słupków) I wady(utrata części informacji) na histogramie i dlatego powinien być stosowany w połączeniu z histogramem. Mogą one być tworzone jednocześnie.. - Kropkowy wykres gęstości ze średnią i standardowymi słupkami błędu
- Nowe schematy kolorów
Dodano 10 nowych schematów kolorów oto ich przykłady

- Ulepszenia legend
Kształty legend
Wprowadzono pionowe, poziome i prostokątne kształty legendy.
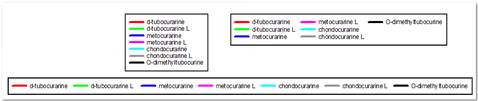
Odwracanie kolejności legend
Można teraz odwrócić położenie pozycji legendy. Zapewnia to bardziej logiczny porządek na niektórych typach wykresów
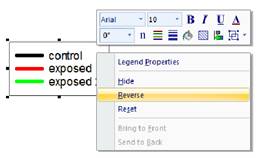
Porządkowanie pozycji legendy
Kolejność elementów legendy można zmienić na trzy sposoby. jak widać poniżej, można przenieść jeden lub kilka pozycji w górę lub w dół legendy za pomocą strzałek góra/dół w panelu właściwości wykresu. Można również wybrać pozycje legendy i użyć strzałek na klawiaturze do przemieszczania, lub wybrać pozycje legendy i przeciągnąć go kursorem myszy do nowego położenia.
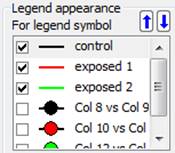
Edycja pozycji legendy przy użyciu mini-paska narzędzi
Dodano możliwość edytowania pozycji legendy poprzez kliknięcie pozycji i użycie mini-paska narzędzi.

Znakowanie bezpośrednie
Wprowadzono możliwość rozgrupowania legendy, dzięki czemu poszczególne pozycje legendy mogą być umieszczone obok odpowiednich wykresów. Etykiety poruszają się na wykresie, utrzymując pozycję względem niego. Dzięki przyleganiu etykiety do wykresu, identyfikacja wizualna każdego wykresu jest teraz znacznie łatwiejsza.
- Funkcje Analizy
- Analiza głównych składowych (PCA)
- Analiza kowariancji (ANCOVA)
- P-wartość dla nieparametrycznej analizy ANOVA
- Kryterium informacyjne Akaikego
- Funkcje prawdopodobieństwa regresji nieliniowej
- Funkcje wagi regresji nieliniowej
Analiza głównych składowych (PCA) jest techniką przydatną przy zmniejszaniu złożoności danych o dużych wymiarach przez przybliżanie danymi o mniejszych wymiarach.
Każdy nowy wymiar jest nazywany jest główną składową i stanowi liniową kombinację pierwotnych zmiennych. Pierwszy główny składnik odpowiada za jak największą możliwą zmianę danych. Każdy następny główny składnik odpowiada za pozostałą możliwie największą zmianę i jest prostopadły do wszystkich poprzednich głównych składników.
Głównych składowych można używać do budowania modeli predykcji. Jeśli większość zmiennych istnieje w podzbiorze o niskim wymiarze istnieje możliwość utworzenia zmiennej odpowiedzi w kategoriach głównych składowych.
Można użyć głównych składowych aby zmniejszyć liczbę zmiennych w regresji, klastrowaniu (analiza skupień) i innych technik statystycznych.
Głównym Celem Analizy Głównych Składowych jest przedstawianie danych za pomocą mniejszej liczby zmiennych zachowując jednocześnie większości całkowitej wariancji.

Jednoczynnikowy model analizy ANOVA oparty jest na randomizowanym projekcie, w którym przedmiotami badań są losowo wybrane z populacji próbki. Wówczas każdy przedmiot jest losowo przydzielany do jednego z kilku poziomów czynnika lub terapii, tak aby każdy przedmiot posiadał jednakowe prawdopodobieństwo otrzymania leczenia.
Wspólnym założeniem tego projektu jest, że badani są jednorodni. Oznacza to, że inne zmienne, w których występują różnice pomiędzy podmiotami nie mają istotnego wpływu na efekt leczenia i nie muszą być zawarte w modelu.
Jednakże istnieją często zmienne poza kontrolą badaczy, które wpływają na obserwacje w jednej lub większej liczbie grup czynników prowadząc do zmian w wartościach średnich grup, błędów, źródła zmienności i wartości P grupy. W tym wielokrotnych porównań.
Zmienne te nazywane są zmiennymi towarzyszącymi. Zazwyczaj są one zmiennymi ciągłymi czasem mogą być również zmiennymi kategorycznymi. Ponieważ maja one zazwyczaj drugorzędne znaczenie dla badania, niekontrolowane przez badacza nie stanowią dodatkowego czynnika wpływającego na efekty, ale mogą być włączone do modelu, aby poprawić dokładność wyników.
ANCOVA (Analiza Kowariancji) stanowi przedłużenie analizy ANOVA otrzymanej poprzez określenie jednej lub więcej zmiennych jako dodatkowych zmiennych w modelu.
Jeśli wprowadzimy dane ANCOVA w arkuszu programu SigmaPlot używając indeksowanego formatu danych, jedna kolumna będzie przedstawiać czynnik a inna kolumna będzie reprezentować zmienna zależną (obserwacje) jak w projekcie ANOVA. Ponadto będziemy mieć jedną kolumnę dla każdej zmiennej towarzyszącej.
Przy użyciu modelu, który obejmuje działanie zmiennych towarzyszących da się wytłumaczyć zmienność wartości zmiennej zależnej. To zasadniczo zmniejsza, niewyjaśnioną wariancją, która jest przypisana do przypadkowej zmienności próbkowania, co zwiększa wrażliwość analizy ANCOVA w porównaniu do tego samego modelu bez zmiennych towarzyszących (modelu ANOVA).
Większa dokładność testu oznacza, że mniejsze średnie różnice pomiędzy terapiami stają się znaczące w porównaniu do standardowego modelu ANOVA zwiększająć w ten sposób moc statystyczną.
Jako prosty przykład wykorzystania analizy ANCOVA można rozważyć eksperyment gdzie studenci sa losowo przypisywani do jednej lub trzech metod uczenia a ich wyniki nauczania są mierzone. Celem doświadczenia jest mierzenie efektów różnych metod i określenie czy jedna z metod zapewnia znacznie wyższy średni wynik niż pozostałe.
Metodami tymi są : wykład, nauka własna i wspólna nauka. W tabelce poniżej w kolumnie z nagłówkiem ANOVA zostały przedstawione wyniki jednoczynnikowej analizy na tych hipotetycznych danych.
Można wnioskować, że nie ma istotnej różnicy między metodami nauczania. Jest możliwe, że studenci w naszym badaniu mogą preferować jedną z metod bardziej niż pozostałe bazując na ich wcześniejszych wynikach w nauce. Załóżmy, że udoskonalenie badań zawiera zmienną towarzyszącą, która mierzy pewną wcześniejszą zdolność, taką jak (SBA).
Wyniki pokazują, że skorygowane średnie są znacząco różne. Metoda wykład jest bardziej skuteczna. Zauważmy, że błędy standardowe średnich zmniejszyły się o czynnik 3 podczas gdy wariancja zmniejszyła się o czynnik 10. Redukcja błędu jest zazwyczaj konsekwencją wprowadzenia zmiennych towarzyszących i wykonania analizy ANCOVA.
ANOVA
ANCOVA
Method
Mean
Std. Error
Adjusted Mean
Std. Error
Coop
79.33
2.421
82.09
0.782
Self
83.33
2.421
82.44
0.751
Lecture
86.83
2.421
84.97
0.764
P = 0.124
P = 0.039
MSres = 35.17
MSres = 3.355
Istnieją cztery wykresy wyników ANCOVA: Linie Regresji w Grupach, Punktowy wykres Reszt, wykres skorygowanych średnich z przedziałami ufności , wykres znormalizowanego prawdopodobieństwa.
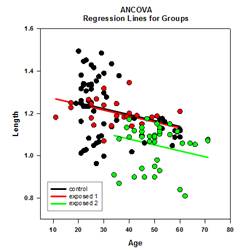
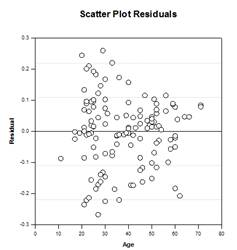

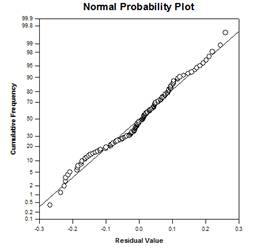
Nieparametrycznymi testami ANOVA w programie SigmaPlot są test Kruskala-Wallisa i test Friedmana. Oba dostarczają cztery procedury testowania post-hoc (po fakcie). Wspomnianymi procedurami testowania są: procedura Tukeya, procedura SNK, procedura Dunna i procedura Dunetta.
Pierwsze trzy procedury mogą być wykorzystywane do testowania znaczenia każdego z porównywanych parami grup leczonych a dwa ostatnie mogą być używane do testowania istotności porównań w stosunku do grupy kontrolnej.
Metoda Dunna jest jedyną procedurą dostępną, jeżeli grupy leczonych mają różną liczebność próby. Gdy stosuje się procedurę testu post-hoc, tabela z listą wyników dla porównań poziomów leczenia dostępna jest w raporcie.
Ostatnia kolumna tabeli pokazuje czy różnica w warstwach jest znacząca czy nie.
W poprzednich wersjach SigmaPlot nie skorygowano p-wartości ponieważ może być porównywana z poziomem istotności ANOVA (zwykle 0,05), aby określić istotność. Spowodowane jest to tym, że SigmaPlot określa istotność poprzez porównanie obserwowanego testu statystycznego, obliczonej dla każdego porównania do wartości krytycznej rozkładu statystycznego otrzymanego z przeglądanej tabeli.
Program SigmaPlot miał dwa zestawy tablic rozkładu prawdopodobieństwa dotyczących czterech metod post-hoc, z których jeden zestaw był dla poziomu istotności 0,05 a drugi dla poziomu istotności 0,01. Zostało to ostatnio zmienione na użycie procedur analitycznych do obliczenia p-wartości tego rozkładu czyniąc tym samym przeglądane tabele nieaktualnymi. Dzięki tej zmianie jesteśmy teraz w stanie skorygować raport p-wartości dla każdej porównywanej pary. Zmiana ta umożliwia także usunięcie ograniczenia używając 0,05 i 0,01 jako jedyne poziomy istotności dla wielokrotnych porównań. W ten sposób użytkownik może wprowadzić dowolny prawidłowy poziom istotności P-wartości od 0 do 1.
Kryterium Informacyjne Akaikego (AIC) dostarcza sposób mierzenia względnej skuteczności w dopasowaniu modelu regresji dla danego zbioru danych. Opiera się ona na koncepcji informacji entropii, kryterium zapewnia względną miarę utraconych informacji w użyciu modelu do opisywania danych. Zapewnia kompromis pomiędzy maksymalizacją prawdopodobieństwa dla estymowanych modeli (tak samo jak minimalizacja residuum sumy kwadratów , jeżeli dane mają rozkład normalny) oraz utrzymywanie liczby wolnych parametrów modelu zmniejszając ich złożoność do minimum.
Chociaż dobre dopasowanie może być ulepszone poprzez dodanie większej ilości parametrów zbyt dokładne dopasowanie zwiększy wrażliwość modelu na zmiany danych wejściowych i może zniszczyć jego zdolności prognozowania.
Podstawowym powodem użycia AIC jest posługiwaniem się kryterium jaki przewodnikiem po wyborze modelu. Obliczenia prowadzone są na zbiorze kandydujących modeli i na danym zbiorze danych. Model z najmniejszą wartością AIC jest wybierany jako model w zbiorze, który najlepiej reprezentuje „prawdziwy” model lub model, który minimalizuje utratę informacji, do szacowania czego przeznaczony jest model AIC.
Po określeniu modelu z minimalnym AIC może być również obliczone prawdopodobieństwo względne dla każdego innego kandydującego modelu do pomiaru prawdopodobieństwa utraty informacji względem modelu z najmniejszym AIC.
Prawdopodobieństwo względne może pomóc badaczom w decydowaniu czy więcej niż jeden model w zestawie powinien być przechowywany do późniejszych rozważań.
Obliczenia AIC opierają się na następującym wzorze ogólnym otrzymanym przez Akaikego.
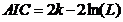
k - liczba estymowanych parametrów w problemie regresji, który zawiera parametry modelu i nieznanej wariancji obserwacji i jest
L - jest maksymalna wartością funkcji prawdopodobieństwa dla estymowanego modelu
Jeżeli rozmiar próbki danych n jest mniejszy w porównaniu do liczby parametrów k, wówczas stosujemy skorygowaną wersje wzoru AIC.
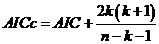
Do biblioteki standardowych funkcji dopasowania zostały dodane 24 nowe funkcje prawdopodobieństwa. Funkcje te, niektóre wzory i kształty wykresów znajdują się poniżej.

Obecnie istnieje siedem różnych funkcji wagi wbudowanych w każde równanie regresji nieliniowej. Funkcje te to między innymi: odwrotność zmiennej y, odwrotność kwadratu zmiennej y, odwrotność zmiennej x, odwrotność kwadratu zmiennej x i Cauchy'ego.

- Funkcje Interfejsu użytkownika
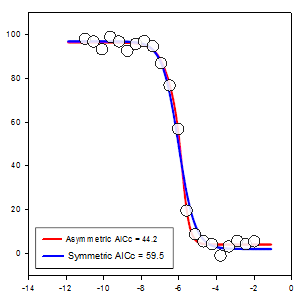
- Zmiana kolejności elementów w notatniku poprzez przeciąganie.
- Nowy samouczek SigmaPlot
Określanie szerokości lini wykresu w kolumnie Arkusza.
Obiekty w sekcji Notebook nie muszą być tworzone po kolei. Teraz można przeciągać elementy w sekcji do nowych pozycji, aby umieścić je w logicznym porządku.
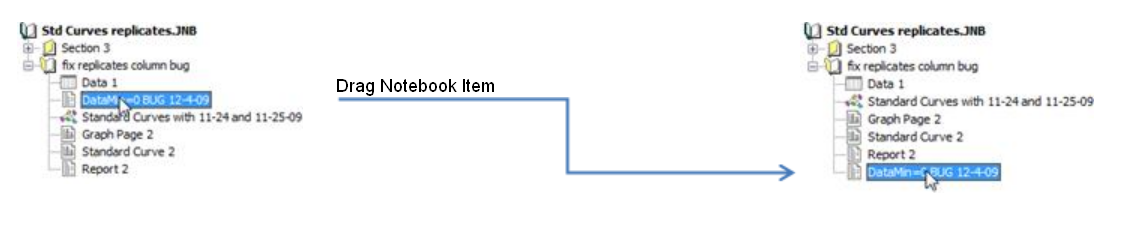
Nowy samouczek sprawia, że tworzenie wykresów od początku jest łatwe. Zaczyna się od prostych przykładów i stopniowo staje się bardziej złożony
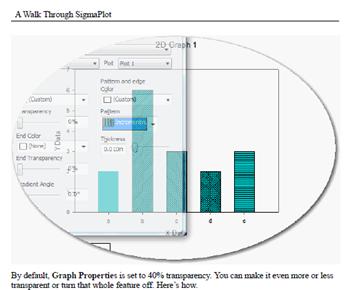
Wartości szerokości linii mogą zostać podane w kolumnie arkusza. Wartości te mogą być stosowane w postaci jednego lub wielu wykresów.
- Funkcje Importu/eksportu
- Nowe Formaty eksportu plików grafiki wektorowej
Dodano formaty: SVG (Scalable Vector Graphics), SWF (Adobe Flash Player) oraz Vector PDF. Są to skalowalne formaty przez co nie tracą rozdzielczości podczas zmiany wielkości. SVG jest standardowym formatem grafiki dla stron internetowych. Format SWF może być użyty za pomocą Adobe Flash Player. Powszechność używania formatu PDF sprawiła, że na głównym pasku programu dołączono przycisk “Create PDF”

- Nowe zaktualizowane formaty importu/eksportu plików niektórych aplikacji.
Możliwość importu i eksportu wersji 13 I 14 plików Minitab, wersji 9 plików SAS i wersji 19 plików SPSS.
- Nowe Formaty eksportu plików grafiki wektorowej
- i wiele innych...
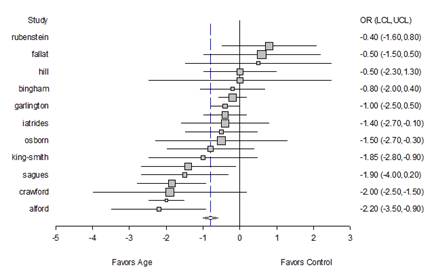
Wykres typu Forest Plot jest jedną z form metaanalizy używanej do łączenia wielu analiz odnoszących się do tego samego zapytania. Metaanaliza statystycznie łączy próbki wszystkich badań w celu stworzenia ogólnego podsumowania, które jest dokładniejsze niż efekt w poszczególnych badaniach osobno. Poszczególne wartości badań i ich 95% przedziały ufności są przedstawione jako symbole kwadratów z poziomymi słupkami błędów i ogólne podsumowanie jako romb z szerokością równą 95% przedziału ufności.
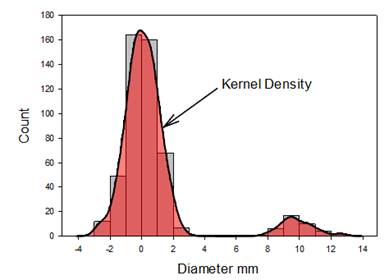
Do kropkowego wykresu gęstości dodano obliczenia dotyczące średniej i standardowych słupków błędu oraz słupki błędu z symbolem. Rozszerza to możliwości wyświetlania na kropkowym wykresie gęstości danych statystycznych takich jak: średnia, mediana, percentyle oraz wykres pudełkowy